Hi, I'm Jahed.
I'm a Software Engineer based in London, United Kingdom.
Most of my projects are related to web technologies and developer tooling, with some game development on the side.
Latest Projects
 FrontierNav Website
FrontierNav Website 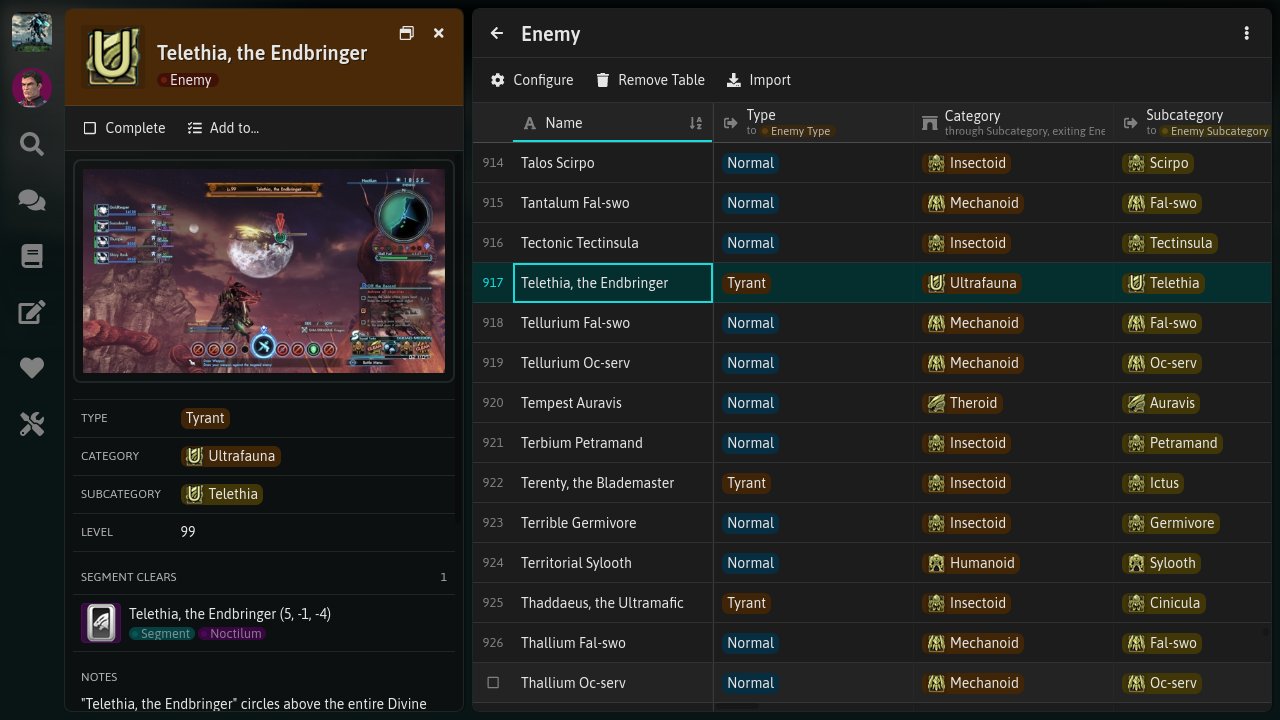
- A wiki platform for creating interactive databases, maps and guides.
 WebVerify Website
WebVerify Website 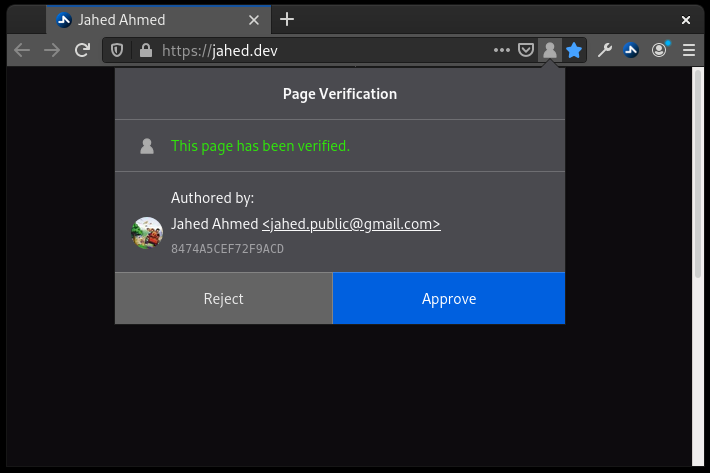
- An approach to verify authorship of webpages using PGP with a proof-of-concept Web Extension.

- Developer tools and libraries spun off from various projects.

Latest Posts
Here's some of my recent posts. Subscribe to my RSS feed to get posts straight to your inbox.
- Running Linux on an ancient Netbook.
- WiFi 6E USB adapters on Linux.
- USB Audio/Video Capture on Linux.
- Fixing air flow in a solid front panel computer case.
- Creating hidden series in Grafana
- Blurring backgrounds correctly with CSS.
- Improved layout on mobile
- Introducing Wiki Pages
- Change Request improvements
- Trying Brave Search