Creating a TP-Link Router Backup Editor for the Web
Following up from the complete waste of time that was editing unnecessarily obfuscated configuration files to disable a ridiculous feature in my TP-Link router, I decided it'd be fun (and convenient) to port the conversion logic in tpconf_bin_xml to the web.
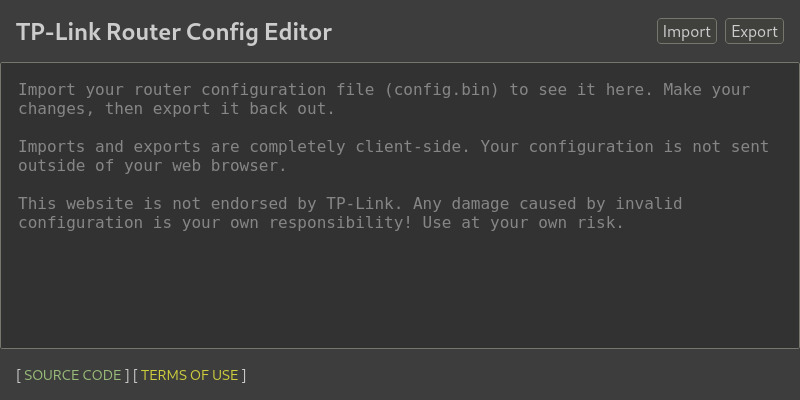
The result was TP-Link Router Config Editor. A simple web page that lets you import TP-Link's config.bin export, make changes to the underlying XML, and re-export the modified config.bin out to import into your router. The process is entirely client-side with no servers involved.
The original script, tpconf_bin_xml.py, has a couple of discrete steps:
- Read
config.bininto a byte array. - Decrypt it using DES. DES is trash, so this was likely only for obfuscation.
- Verify the integrity header using MD5.
- Decompress the contents.
- XML!
There are variations of this process depending on the router model, but these are all of the known pieces. To get this into JavaScript, we needed the following APIs:
- Read
config.bininto anArrayBuffer. - Use CryptoJS to decrypt.
- Use CryptoJS to verify integrity.
- Decompress the contents by porting over the logic in
tpconf_bin_xml.py. - Convert the
ArrayBufferinto XML usingTextDecoder.
This looks pretty simple, but there were multiple steps and APIs involved to get this all working.
State of the Minimal Web
One of the limitations I set myself with this small project was to not use any external dependencies. No Webpack, Babel, TypeScript, SASS, Jest, NPM, and so on. Just pure HTML, CSS and JS. I don't need broad compatibility for this and I wanted to see where the web ecosystem is currently at.
I broke that rule a bit almost immediately. The only way to use DES and MD5 is through a third-party library. I tried keeping it minimal but most smaller libraries didn't seem to work. CryptoJS did so I stuck with it.
Testing was also an issue. I could write my own browser testing framework, but that's a lot of work. I didn't get around to finding a minimal solution. It'd probably involve an automation generator and a not-so-minimal runner.
Everything else went great. I could use all the syntax I was familiar with across the stack. Web development outside the big frameworks is in a good place.
Working with Byte Arrays
JavaScript's ArrayBuffer API is simple. They're byte arrays. The hard part is adapting yourself to not treat them like regular arrays. I don't work with binary much so it took a while to wrap my head around it, while also porting different APIs between Python, a language I don't use much, and JavaScript.
Python has a struct library which tpconf_bin_xml.py uses. The library uses "format characters" as type indicators. This is what the script uses:
H, a 2 byte unsigned short.I, a 4 byte unsigned int.
In JavaScript's typed arrays:
Hports toUint16, a 2 byte unsigned short.Iports toUint32, a 4 byte unsigned long.
The part that tripped me was:
L, a 4 byte unsigned long.
On the surface, it looks like L should map to Uint32. So then what's I? I eventually just mapped I to Uint32 too and it worked fine. L isn't used in the script anyway.
struct's documentation itself confused me. Probably because I'm not familiar with Python, C or binary lingo. "Packing" and "unpacking" just means setting and getting various bytes in a byte array. The APIs map pretty much one-to-one with JavaScript's DataView API.
Strings and Bytes
Doing any sort of web search for converting strings to bytes and back will likely lead you down the wrong path. Do not use fromCharCode, charCodeAt or whatever. It's all wrong. Strings are complicated in JavaScript. Use the TextDecoder API instead (and TextEncoder). It works with typed arrays which is ideal in this scenario.
The main hurdle I had here was knowing if something even works. Strings are so complicated, I never really knew if a conversion was good enough. Especially with TP-Link's weird format. Did I miss any corner cases? At some point, I decided to trust TextDecoder. It seems to work.
Operator Precedence
Once I got everything ported, there was a bug. I didn't know where in all the binary manipulation I just ported. So, as usual, after a few hours of reading documentation and refactoring, I added some log lines to get a printout of every state change in both scripts and compared them. Somewhere in the middle, they went out of sync, and I pinned it down to this line:
ldb & bits > 0 # Python, boolean// prettier-ignore
ldb & bits > 0; // JS, numberTwo issues here:
- Operator precedence. Python does the
&first. JavaScript does the>first.- Adding some brackets fixes this. They should've been there anyway.
- Dynamic types.
- Fixing the order issue solves this difference, but it did make it harder to debug.
Using ArrayBuffers
As I mentioned before, ArrayBuffers and typed arrays aren't regular arrays and it's important not to treat them like such. Typed arrays are views of the same ArrayBuffer. They are essentially DataViews with a convenient array-like API.
Using view.slice creates a new ArrayBuffer which isn't great. If you're using views on a potentially large ArrayBuffer, you probably want to avoid duplication. Use view.subarray instead which creates a another view over the same ArrayBuffer.
Also, if you see an API only taking an ArrayBuffer (like DataView) and you have a view, doing this is wrong:
new DataView(view.buffer)Here we've expanded a potentially limited view to the entire buffer. The new view will contain the entire buffer rather than just the bytes within that view.
I personally don't like that this is even possible. A function which is given a view shouldn't be able to look beyond the view it was given. It's a leaky abstraction which makes it easy to trip up. That aside, to use this approach, you'll need something like:
new DataView(view.buffer, view.byteOffset, view.byteLength)I needed to do this as I was using Uint8Array to pass around the byte array. Most APIs use Uint8Array as it's a 1-byte array so it's a good default. However, some steps used other formats, so I needed to create multiple views of the same ArrayBuffer.
DES and MD5
The SubtleCrypto API supports some cryptographic algorithms. Unsurprisingly, since it's so new, it does not support DES or MD5 which are old and busted. For that, the best thing we've got is CryptoJS.
Since I don't want external dependencies, I vendored CryptoJS's web bundle so that it's in my source repository. Vendoring has various advantages when dependencies are limited like this. For one, the project won't be tied to NPM's registry, nor NodeJS.
CryptoJS is huge, and the bundle contains many algorithms I won't use. Its module system is a bit dated and it would be nice to only vendor the parts I need. Doing that though would require refactoring CryptoJS. I tried, there's a lot of code. I might do it in the future.
CryptoJS WordArray
CryptoJS is pretty old and stable. It doesn't seem to have been made for NodeJS or web browsers, but rather both. It avoids using the web's ArrayBuffer and NodeJS's Buffer. Both do similar things but I think ArrayBuffer is fairly recent. Instead it uses its own WordArray objects. Here's what it looks like:
type WordArray = {
sigBytes: number; // number of bytes
words: number[]; // 4 bytes per item
// and some other methods
};To handle this type, CryptoJS provides a handful of converters including hex strings and base64. Initially I used both. When I had a byte array, I could easily convert it to a hex string. When I had a blob I could easily use base64. Of course, that added 2 conversion steps every time I wanted to encrypt, decrypt or hash something. Horrible.
As I got more familiar working with ArrayBuffers, it was pretty trivial to switch a byte array to a WordArray using some bit shifts and bitwise operations. A "word" is 4 bytes appended one after the after.
It still kind of sucks that I need to convert anything at all, but as mentioned before, modifying CryptoJS is a lot of work. I might put some time into it in the future.
Triggering Downloads
Something that isn't very well documented is how to trigger downloads of in-memory blobs. FileSaver.js is typically recommended for this, but I felt it's actually not needed. Since I'm going minimal here, I figured it's pretty simple. Working with blobs for FrontierNav helped as I knew which APIs to combine.
const file = new File([encrypted.buffer], "config.bin", {
type: "application/octet-stream",
});
const url = URL.createObjectURL(file);
setTimeout(() => URL.revokeObjectURL(url), 60_000);
window.open(url);That is pretty much it. The only odd thing is the setTimeout but it's needed as createObjectURL will hold onto the blob forever and cause a memory leak. So revokeObjectURL releases it. There's no API to hook into the download's progress so a generous timeout is the best we can do.
Conclusion
Once I got everything tied together and working, the project was a mess. That's not surprising since I figured it all out as I went. Refactoring everything was more therapeutic than anything else and the source code looks trivial now.
Having written this all up, it kind of shows just how much is involved in all of this. Porting a simple Python script requires so much knowledge. The end result is a simple web page with two <button> elements and a <textarea>.
Thanks for reading.